 8.1 C#の文字列 8.1 C#の文字列 |
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
| 番号 | 以下をクリックすると,該当箇所にジャンプします |
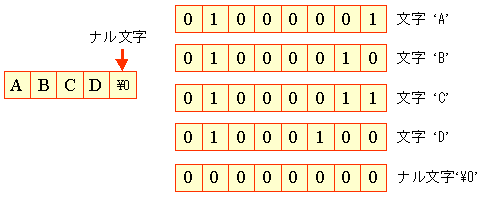
| (1) | 文字列リテラル |
| (2) | 文字列コードを確認するプログラム |
| (3) | 配列による文字列 |
| 番号 | 以下をクリックすると,該当箇所にジャンプします |
| (1) | 文字列リテラル |
| (2) | 文字列コードを確認するプログラム |
| (3) | 配列による文字列 |
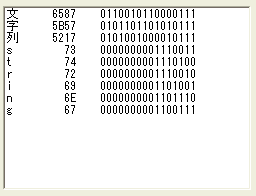
| private string binaryScaleString(long V) { long VV=V;string S=""; for(int i=0;i<16;i++, VV /=2 ) S = ((VV % 2 ==0) ? "0" : "1") + S; return S; } private void strDump(string S) { listBox1.Items.Clear(); for(int i=0;i<S.Length;i++) { long V=(long)S[i]; string X = V.ToString("X"); string B = binaryScaleString(V); if(X.Length==2) X = " " + X; listBox1.Items.Add (S[i].ToString() + "\t" + X + "\t" + B); } } private void button1_Click(object sender, System.EventArgs e) { strDump("文字列string"); } |
| 番号 | 以下をクリックすると,該当箇所にジャンプします |
| (1) | 文字列リテラル |
| (2) | 文字列コードを確認するプログラム |
| (3) | 配列による文字列 |
| 番号 | 以下をクリックすると,該当箇所にジャンプします |
| (1) | 文字列リテラル |
| (2) | 文字列コードを確認するプログラム |
| (3) | 配列による文字列 |